RBAC介绍以及如何设计一个简易且高可用的RBAC1的鉴权系统
一.RBAC0,RBAC1,RBAC2,RBAC3
RBAC,即为以角色为基础的访问控制,不同于把权限赋予用户,而是把权限赋给角色,用户获得角色,是一种非常灵活的鉴权设计
其设计围绕着 用户 角色 权限(功能) 展开
(一)RBAC0
RBAC0又叫扁平 RBAC(Flat RBAC),用户通过角色获取权限;通过多对多分配;用户可同时使用多个角色的权限 ;有用户-角色审查(能知道一个用户有多少角色)
假如有这么一个架构:
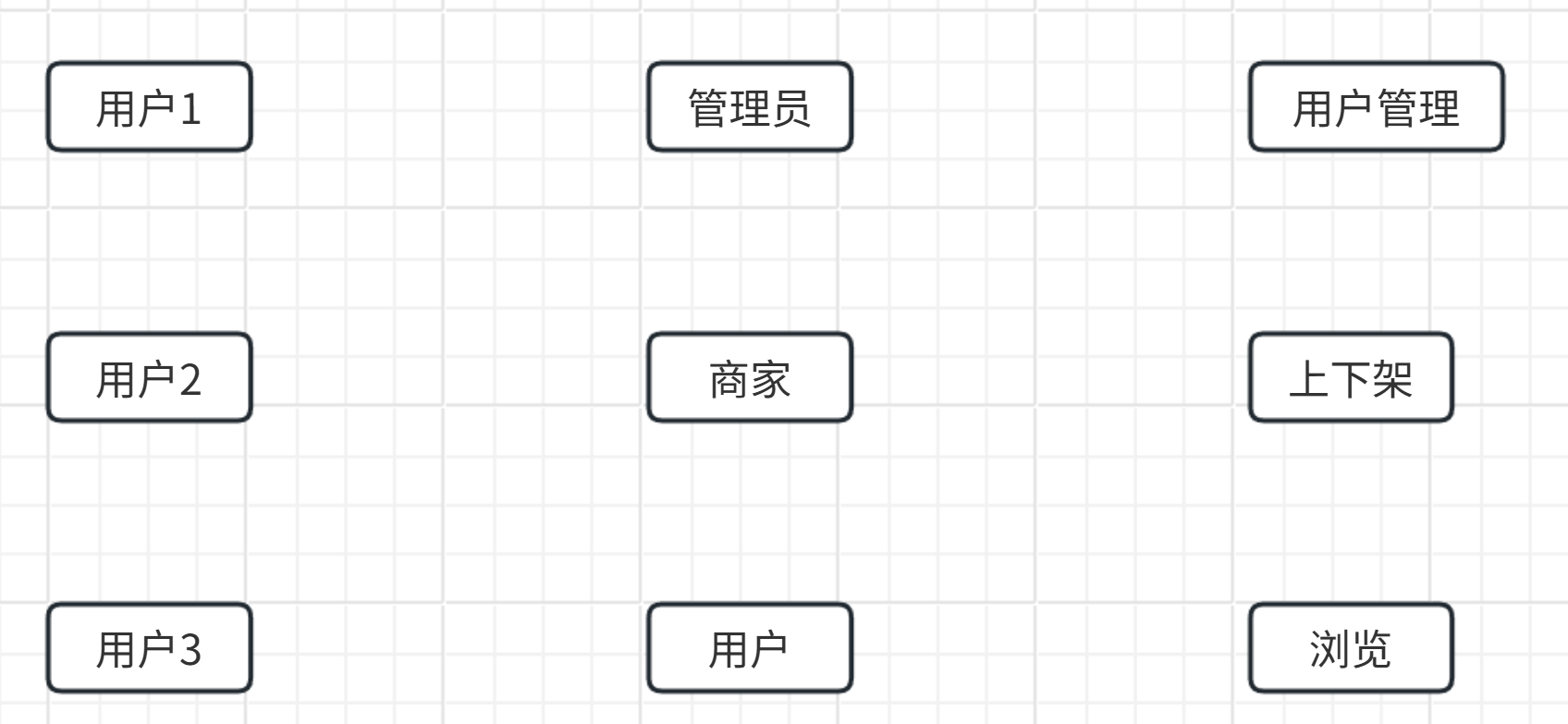
需要用RBAC0对其进行鉴权,结果会是这样:
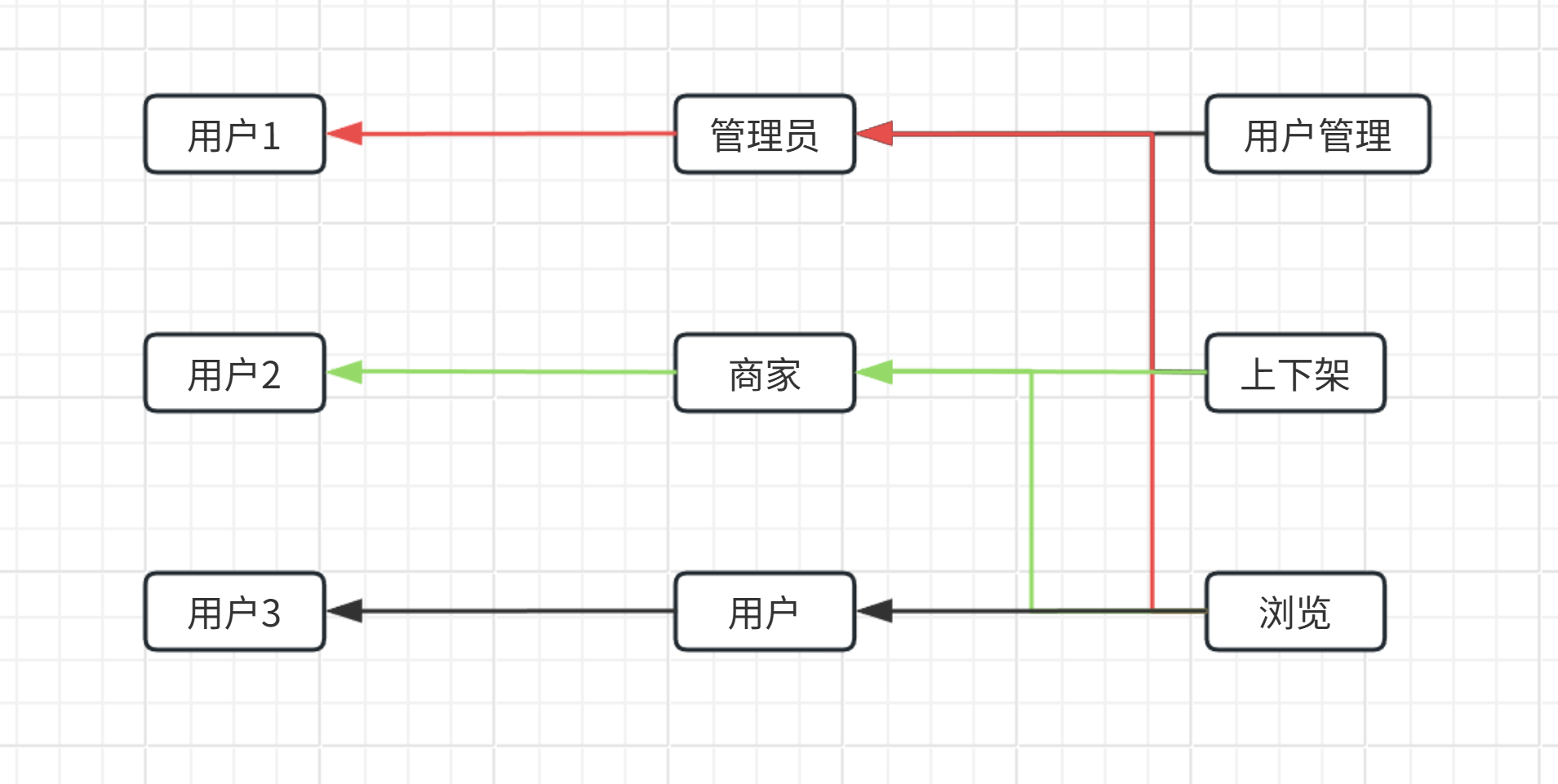
如你所见,非常丑陋且复杂
RBAC0不适用于处理权限复用的情况,更适应每个角色的权限都不同的情况
(二)RBAC1
RBAC1又叫层次 RBAC(Hierarchical RBAC),**包含扁平 RBAC **,支持角色层次结构(偏序关系),支持任意层次结构(2a型),支持受限层次结构(如树状)(2b型)
翻译成人话就是在RBAC0加入了继承系统,举个例子:
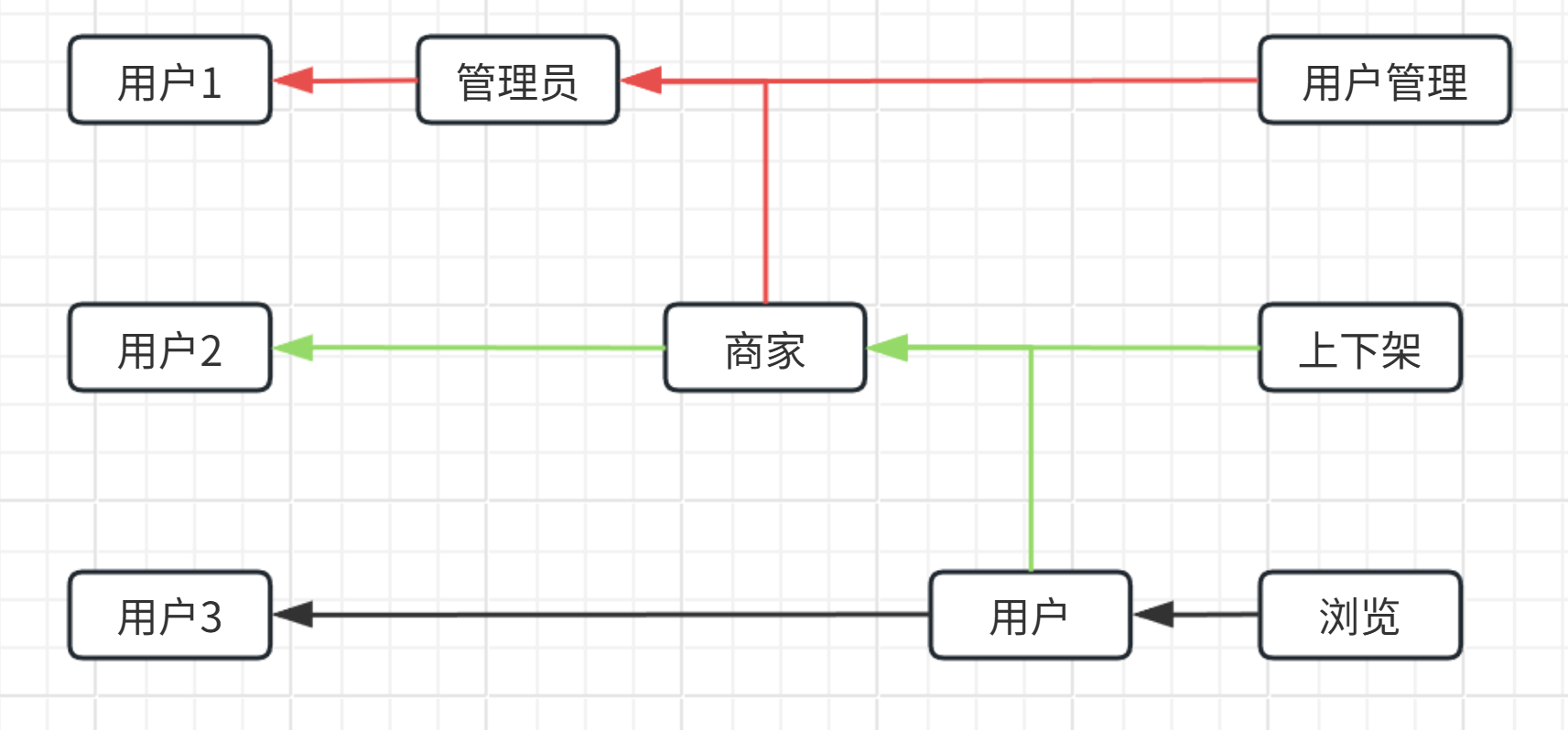
这就是一个典型的2b型的RBAC1系统,角色之间有偏序关系,可以继承:一个角色可以同时继承多个父角色的权限,获得了管理员权限就获得了商家,用户的权限
(三)RBAC2
RBAC2又叫受限 RBAC (Constrained RBAC),包含层次 RBAC, 必须强制执行职责分离(SOD),3a/3b: 分别对应任意或受限层次结构 。
SOD通过将行动或任务的责任和权限分散给多个用户,来减少欺诈和意外损害的可能性 ,也就是说不能当选手又当裁判
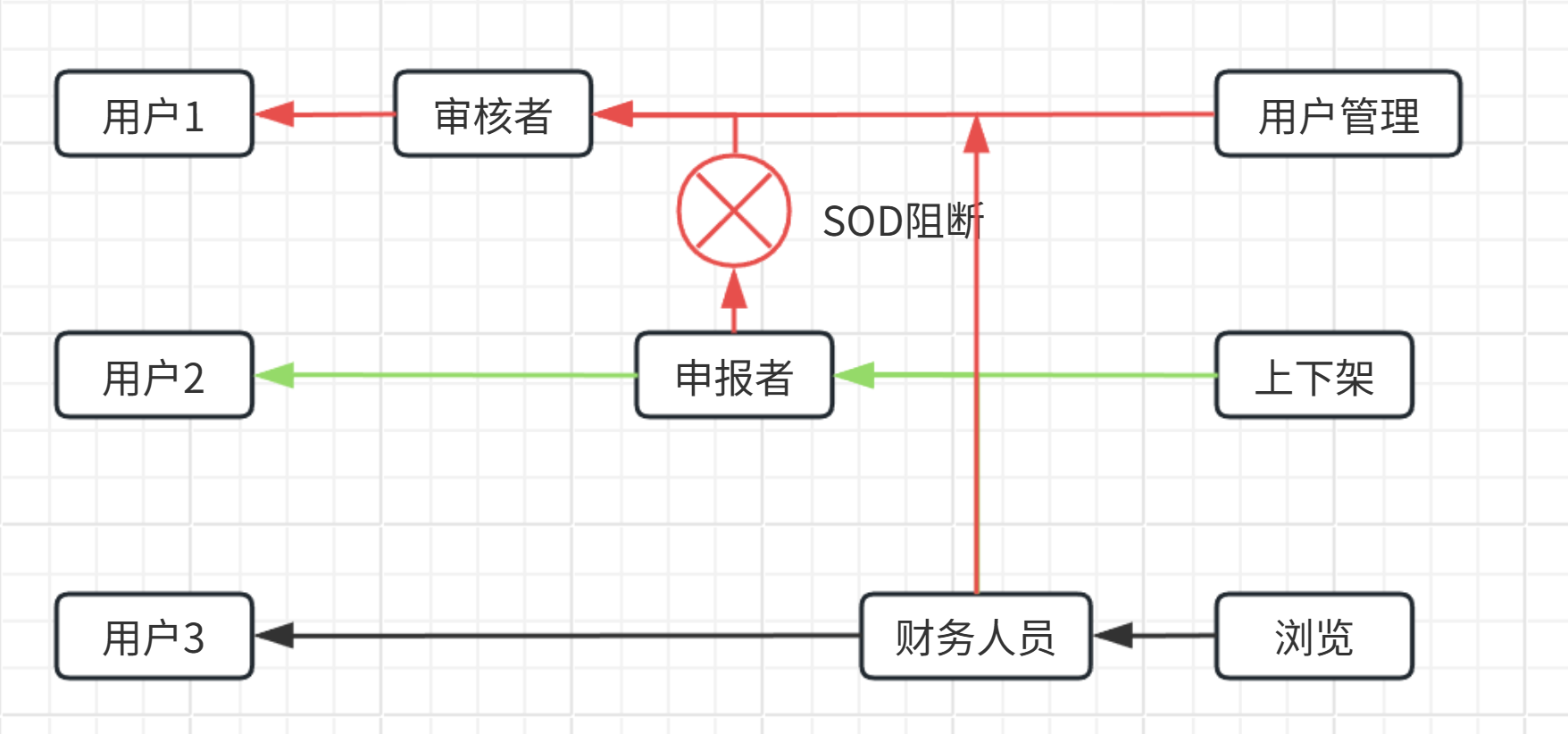
本质上就是RBAC1 + SOD,要求要么具有SSD(静态职责分离,直接禁止你当选手又当裁判)**,要么具有DSD(动态职责分离,允许你当选手又当裁判,但不能同时当)**
较为复杂,SOD靠业务实现
(四)RBAC3
RBAC3又叫对称 RBAC(Symmetric RBAC),**包含受限 RBAC ** ,支持权限-角色审查(Permission-Role Review),其性能需与用户-角色审查相当
类似于RBAC0的用户-角色审查。系统必须能够知道特定角色分配了哪些权限,以及特定权限被分配给了哪些角色
也就是加入了一个反推的操作,且性能要相当
既能role->perms,也能perm->roles
为什么这里会单独提出一个反推的功能?
因为它在大型分布式系统中本质上很难实现。
- 非对称性: 大多数访问控制系统是为了快速回答“用户 X 能做什么?“而优化的,以便在用户登录或访问资源时快速鉴权。
- 反向查询昂贵: 要回答“谁拥有权限 Y?”,通常需要反向遍历整个权限映射表。在拥有成千上万个权限和角色的系统中,如果系统架构不支持双向索引,这种查询的性能消耗巨大,类似于数据库中的全表扫描。
如何设计一个高可用的RBAC1系统
首先,在你要设计前,你应当知道你们业务的需求来决定应该选用哪一个级别的RBAC
实际上,在真正的生产应用阶段,绝大多数企业都是采用基于RBAC1,RBAC0或其变种再加上RBAC3的反推,因为SOD,层级其实很难实现
但无论如何,RBAC鉴权系统的思路其实大差不差:访问快速,能承受一定压力,内存占用不大,支持热修改,支持分布式
这里我以一个标准的RBAC1进行演示
(一)系统分析
这里以Java为例
首先,鉴权系统必须处于系统最前方,但是有些接口并不需要鉴权,如何实现?我们大可以把鉴权放在拦截器,然后像SpringSecurity那样维护一个匹配表匹配哪些URL要鉴权,哪些URL要什么角色来访问,但既然引入了RBAC,本身就是为了更方便更细粒度的去鉴权。这里我给出的方法是设计一个注解,注解参数是访问此接口所需的权限,用AOP拦截具有这个注释的方法,检查访问的User有没有权限
为了获得访问的userId,可以采用ThreadLocal来存储,在网关截取Token放入Threadlocal
但我这里建议不要用ThreadLocal,直接在请求中注入userId到请求参数中,AOP中就从请求参数中拿带userId,这样用着更加方便,也避免了ThreadLocal内存泄漏的风险(概率极低)
具体来说:
x
public CurrentUserId {}这个注释用来放在userId前,用于AOP拿到userId,否则就需要从元数据中拿,非常不便
x
// 作用在方法上 // 运行时有效public RequirePermission {
/** * 需要的权限标识,例如: {"user:add", "user:edit"} */ String[] value();
/** * 校验逻辑:AND (所有权限都要有) / OR (只要有一个权限即可) * 默认为 AND */ Logical logical() default Logical.AND;
enum Logical { AND, OR }}这里支持 或,与
x
public void checkPermission(JoinPoint point) { // 1. 获取注解详情 MethodSignature signature = (MethodSignature) point.getSignature(); Method method = signature.getMethod(); RequirePermission annotation = method.getAnnotation(RequirePermission.class); if (annotation == null) { return; }
// 2. 获取当前登录用户拥有的权限集合 (从 请求 中拿)
Annotation[][] paramAnnotations = method.getParameterAnnotations(); // 获取所有参数值 Object[] args = point.getArgs(); Long currentUserId = null; for (int i = 0; i < paramAnnotations.length; i++) { for (Annotation a : paramAnnotations[i]) { if (a instanceof CurrentUserId) { // 找到了!返回对应的参数值 currentUserId = (Long) args[i]; break; } } } if (currentUserId == null) { throw new NoAuthorityException(401,"无法获取当前用户 ID,权限校验失败"); } Set<String> roleKeys = redisAuthorityService.getUserRoleKeys(currentUserId); if (roleKeys == null || roleKeys.isEmpty()) { throw new NoAuthorityException(403, "用户暂无角色权限"); }
// 3. 获取接口要求的权限 String[] requiredPerms = annotation.value(); RequirePermission.Logical logical = annotation.logical();
// 4. 开始校验 HashSet<String> functionSet = new HashSet<>(); for (String roleKey : roleKeys) { functionSet.addAll(redisAuthorityService.getRoleFunctionKeys(roleKey)); } check(functionSet, requiredPerms, logical);}用的时候就只需要这样:
x
public String hello( Long userId) { return "hello";}非常的简单方便!
(二)鉴权流程分析
鉴权需要有 访问快速,能承受一定压力,内存占用不大,支持热修改,支持分布式的特点,那Redis便是一个非常好的一个选择
我们维护 user:{userId} = Set(roleKey) 和 role:{roleKey} = Set(functionKey)
假如有一个用户进来,我们根据其userId到Redis查其role,再根据其role去拿到对应的functionKey,然后比对该注释中要求的功能(权限)这个用户满不满足,满足的话就放行,反之拦截
思路很简单,但有很多细节:用户的role是有继承关系的,假如一用户有一个role是admin,他可能继承了来着商家,用户的众多functions,Redis里面的role->functions也必须是己继承的,不然每一次鉴权都要去递归继承
这是一个典型的为了读而牺牲写,但鉴权本身就是更倾向于读
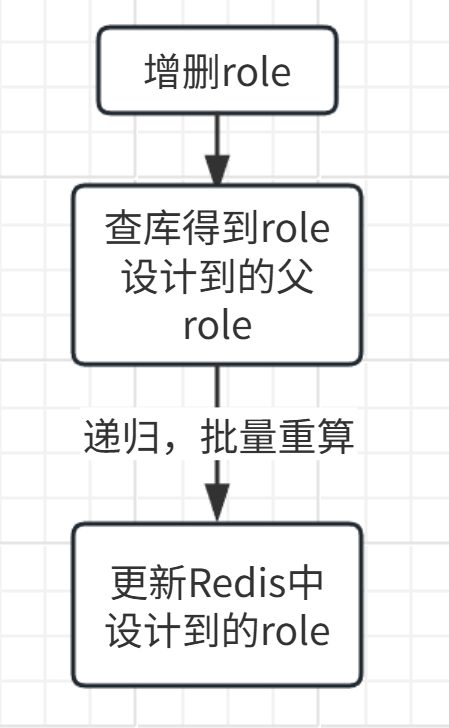
在修改role的functions时,需要递归的修改其父角色(继承它的角色)的functions,这是一个较为消耗性能的操作,但是role本身数据不多,还能接受
不采用user->functions的理由是,隐去了role,导致修改role的时候需要有一个反向索引去找到该role的user,这极其消耗性能,而且user数量众多,很占用内存,这也就是RBAC3的问题
而且为了节省内存,user->role也应该采用懒加载,不然用户数一多,一次加载直接卡死
对于TTL,user->role应该有TTL,一天半天都可,role->functions可以把TTL设为较长,因为这个数据本身修改的频率不大,在修改的时候修改即可
下面是流程图:
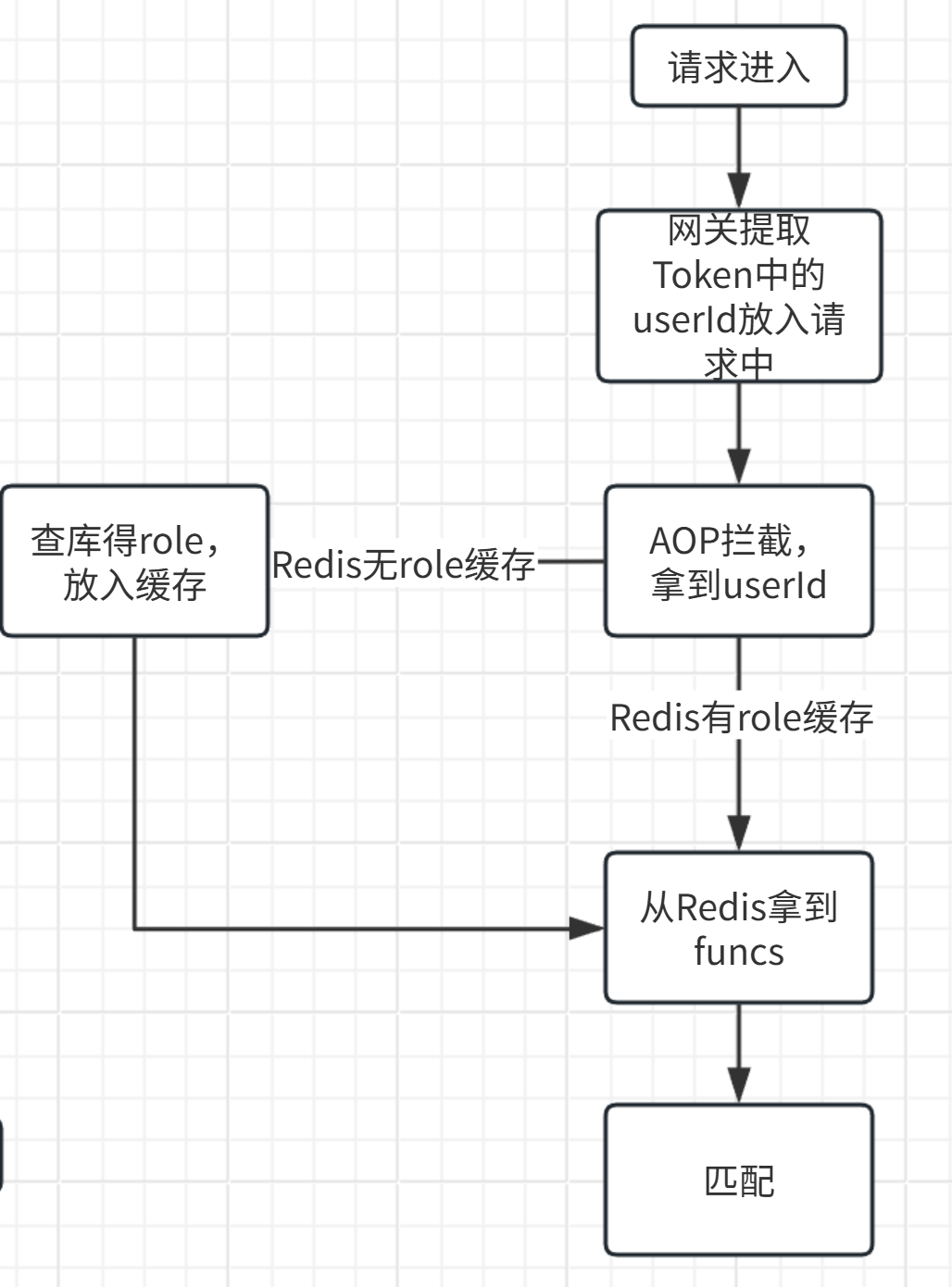
修改流程:
大致流程便是如此,对于RBAC的更详细的介绍可以看The NIST Model for Role-Based Access Control: Towards a Unified Standard
也可以看我在github中的小demo:Thanwinde/tree-authority: 一个简单的基于RBAC1的鉴权系统